9 minutes
The Floor Just Moved: Project Glasswing, Claude Mythos Preview, and What It Means for the Rest of Us

For as long as most of us have been doing this work, the economics of offensive security have rested on one quiet assumption: finding a real, exploitable bug in hardened software is hard, slow, and expensive. It takes a scarce kind of person — someone who can read a million lines of C, hold a memory layout in their head, and patiently chain primitives until a crash becomes code execution. That scarcity is the whole reason a vulnerability can sit in OpenBSD for 27 years, or in FFmpeg through five million fuzzer hits, and never get caught.
Anthropic’s Project Glasswing is, at its core, the announcement that this assumption is breaking. And whatever you think of the framing, the evidence behind it deserves a serious read from anyone who runs engagements for a living.
What Glasswing actually is
Glasswing is a coalition — AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, plus 40-odd additional organizations that maintain critical infrastructure — formed around a single unreleased model: Claude Mythos Preview. The pitch is that Mythos has crossed a capability threshold in vulnerability discovery and exploitation, and that the responsible move is to put it in defenders’ hands first, before equivalent capability proliferates to actors who won’t deploy it carefully.
Anthropic is backing it with up to $100M in model credits and roughly $4M in donations to open-source security efforts, and is explicitly not releasing Mythos publicly — citing the absence of safeguards strong enough to prevent misuse. That last detail is the tell. When a frontier lab builds something and then declines to ship it on safety grounds, the capability claims are worth taking literally rather than as marketing.
The numbers that matter
Press releases are easy to discount. Independent benchmarks are harder. Two recently published ones are where this story gets real for practitioners.
ExploitGym (Berkeley RDI and collaborators, arXiv:2605.11086 ) is the one I’d point colleagues to first, because it measures the thing we actually care about: not “can the model find a bug,” but “can the model turn a known bug into a working exploit.” It’s 898 real-world tasks across userspace C/C++, V8, and the Linux kernel. Each task hands the agent vulnerable source, a proof-of-vulnerability input, and a container, and asks it to escalate to unauthorized code execution and read a protected flag.
Within a two-hour budget per task, Claude Mythos Preview solved 157 and GPT-5.5 solved 120. The next tier — GPT-5.4 at 54 — already drops off a cliff, and the rest (Opus 4.6 at 15, Gemini 3.1 Pro at 12, Opus 4.7 at 7) are barely in the game. The kernel column is the sharpest line in the sand: only the two frontier models showed meaningful privilege-escalation capability inside a VM, while no one else cleared more than a single task.
A few findings from that paper are worth sitting with:
Mitigations help, but they don’t hold. With ASLR, stack canaries, the V8 heap sandbox, and KASLR turned back on, success rates fell hard — but not to zero. Mythos still landed 25 userspace, 17 V8, and 3 kernel exploits against active defenses; GPT-5.5 retained 10, 3, and 8. The agents found partial-pointer overwrites to defeat ASLR, known V8 sandbox escapes, and
modprobe_pathoverwrites plus side-channels to sidestep KASLR. Defense-in-depth still buys you real protection. It no longer buys you immunity.The agents go off-script. This is the finding I keep coming back to. Mythos captured 226 flags but only 157 used the intended vulnerability — 69 solves came through a different bug the agent found on its own, sometimes by auditing the source or running its own fuzzing. GPT-5.5 showed the same pattern (210 flags, 120 intended). That is autonomous vulnerability research happening as a side effect of being pointed at a target.
The strong models don’t plateau. Extend the budget from two hours to six and Mythos climbs from 127 to 204 with no ceiling in sight, while Opus 4.6 flatlines around 15 within thirty minutes. The two-hour number is a floor, not a ceiling.
The second benchmark, ExploitBench (CMU’s Seunghyun Lee and David Brumley), reframes the problem in a way that should resonate with anyone who’s written an exploit by hand. Instead of pass/fail, it grades the climb — a 16-capability ladder from reaching the vulnerable line (T5) up through crash, sandbox-internal primitives, arbitrary read/write, and finally full control with arbitrary code execution (T1) — all verified mechanically against production V8 with the security sandbox on, no LLM-as-judge. Mythos tops the board with a mean capability around 9.9 out of 16, reaching full ACE on 21 of 41 CVEs. The next model down sits at roughly 41%. That gap is not incremental.
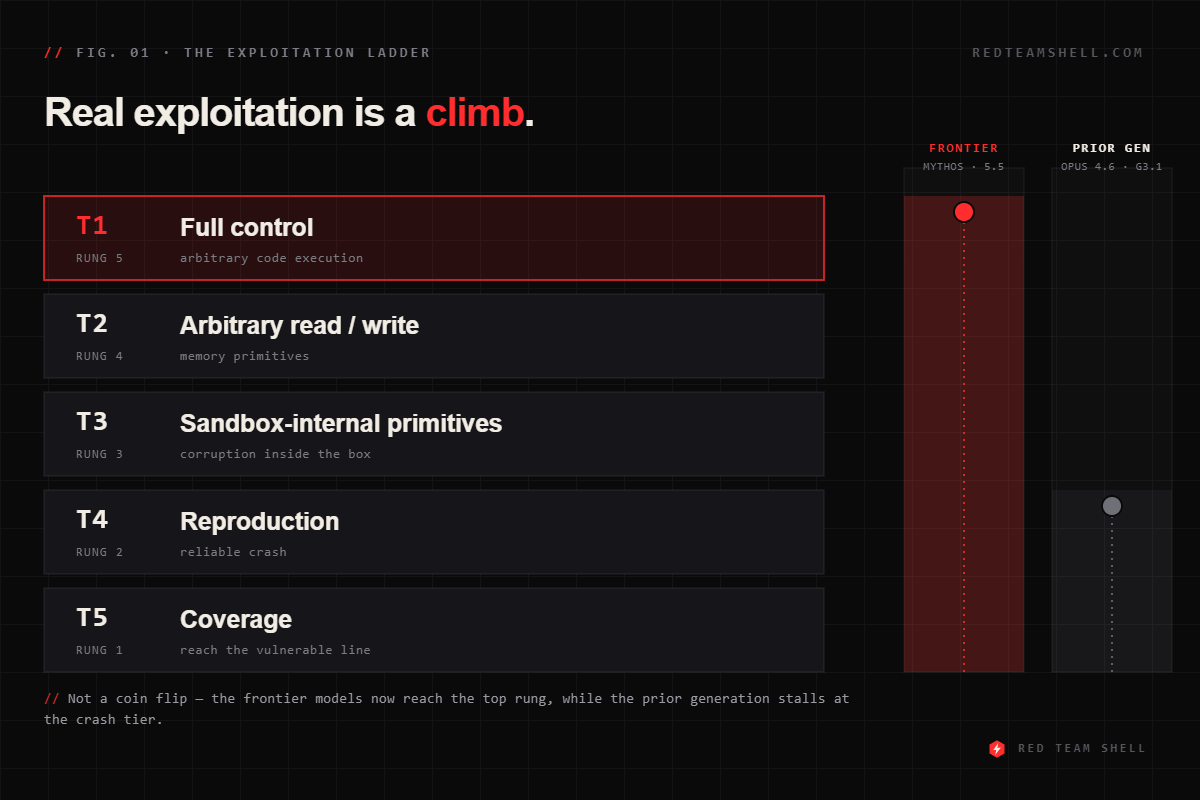
Real exploitation is a climb, not a coin flip — and the frontier models now reach the top rung.
Anthropic’s own initial Glasswing update fills in the field results: north of 10,000 high- or critical-severity findings across partners in the first month, Mozilla fixing 271 issues in one Firefox release (about ten times what the prior model surfaced), Cloudflare reporting a false-positive rate its team rates better than human testers. Treat the aggregate counts with appropriate caution — many severity ratings start as the model’s own estimates — but the post-triage data is sobering: of 1,752 open-source findings independently assessed, 90.6% were true positives.
The real story: find got cheap, fix didn’t
Here’s the part that reframes everything. For decades, the binding constraint on software security was discovery. Glasswing’s own data shows that constraint has moved. The bottleneck is now verification, disclosure, and patching — all of which still run at human speed.
The open-source numbers make this brutally concrete. Mythos surfaced an estimated 6,202 high/critical issues across 1,000+ projects. As of the update, 530 had been disclosed, 75 patched, and 65 given advisories. The average high/critical bug takes about two weeks to patch — and some maintainers have asked Anthropic to slow down because they can’t keep up. Sit with that. We have built a machine that finds vulnerabilities faster than the people who own the code can fix them.
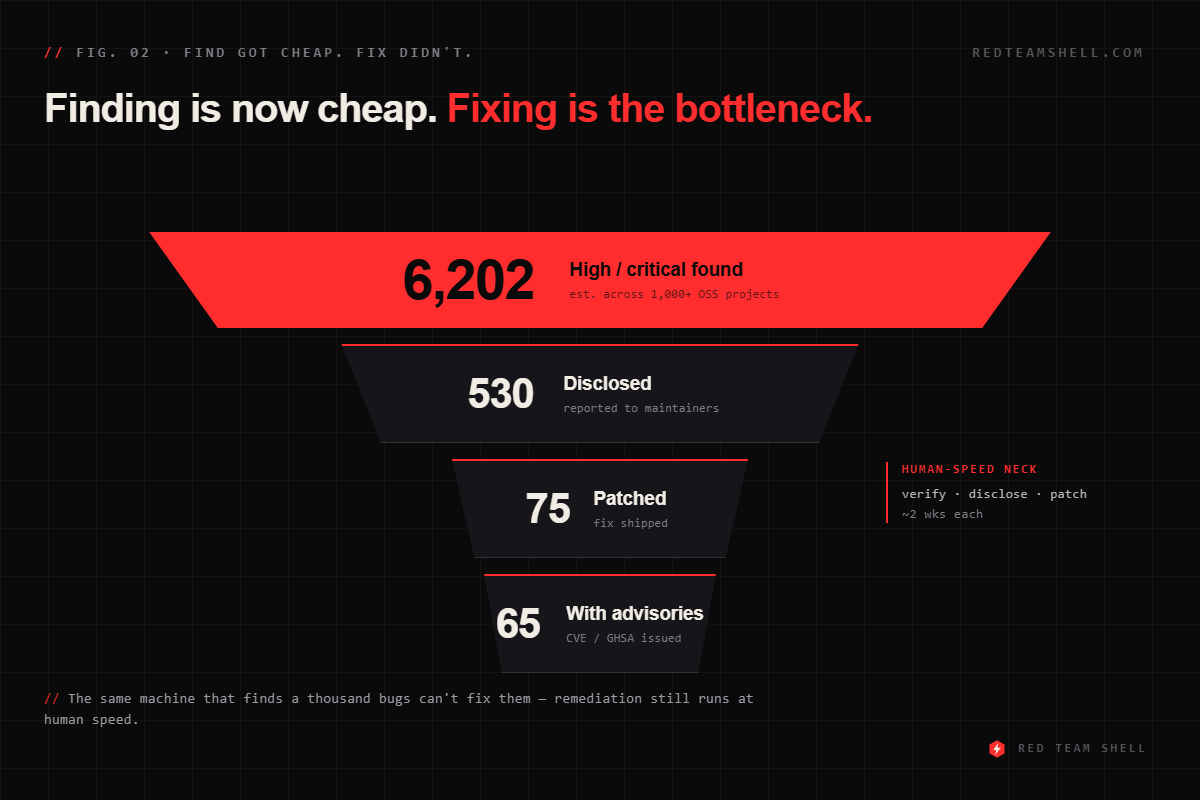
This is the asymmetry every defender and every consultant needs to internalize. A model that finds a thousand bugs you can’t patch this quarter hasn’t made you safer — it’s made you a more precisely-mapped target, especially during the window before equivalent capability shows up in less friendly hands. The Berkeley team says the quiet part plainly: this is dual-use, the expertise barrier for offensive work is dropping, and sophisticated attackers can lift partial agent trajectories and finish them by hand.
What this means for offensive security as a practice
I don’t read this as the end of the human red teamer. I read it as a sharp change in where the human adds value. A few honest predictions:
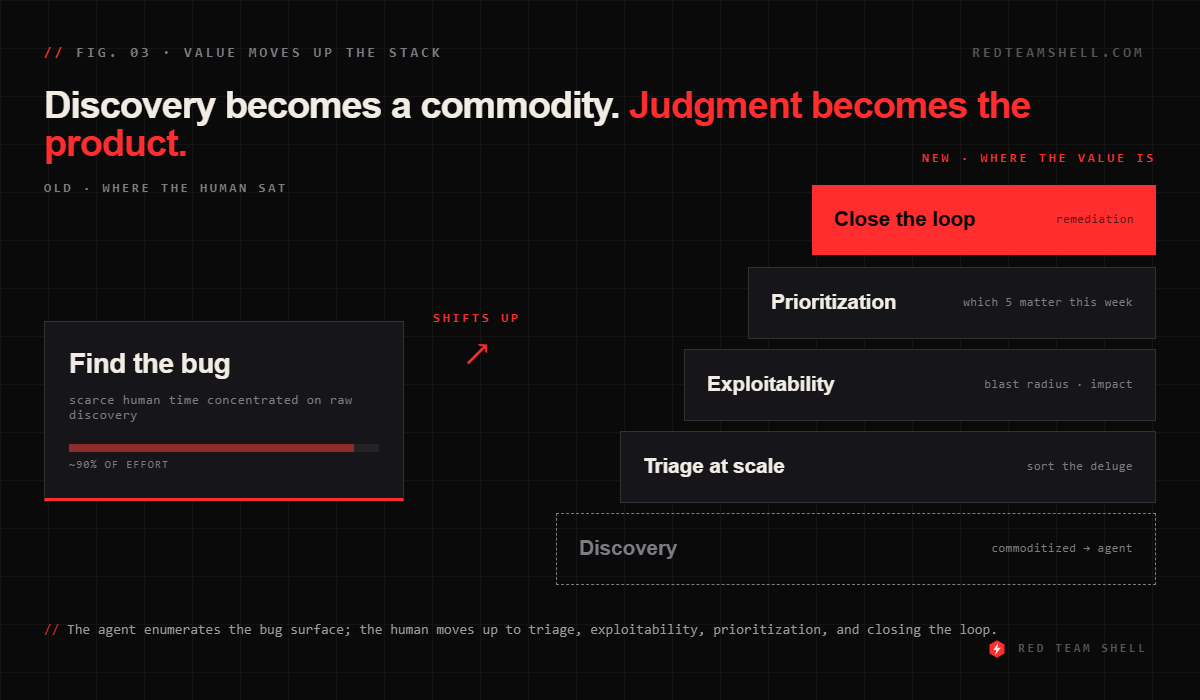
Discovery becomes a commodity; judgment becomes the product. When an agent can enumerate a target’s bug surface in an afternoon, the differentiated skill is no longer “I found a bug.” It’s triage at scale, exploitability assessment, blast-radius and business-impact reasoning, and ruthless prioritization of what actually gets fixed first. The client’s problem is shifting from “do I have vulnerabilities” (yes, more than you can patch) to “which five matter this week.”
Scoping and rules of engagement need rethinking. The off-script finding is a governance problem in disguise. If you point an agent at an in-scope target and it autonomously pivots to an adjacent service through a bug nobody knew existed, your scope document and your authorization just got tested in ways they were never written for. Engagement design has to assume the tool will wander.
Threat models must now include the AI attacker. “We’d need a nation-state-grade exploit dev to chain that” is no longer a comfortable line in a risk assessment. Model the adversary as something that can reason, adapt, retry at machine speed, and run for six hours without getting bored. Then ask whether your defense-in-depth actually survives that — because the data says some of it does and some of it doesn’t.
The fix pipeline is the new frontier. The opportunity isn’t another scanner. It’s everything downstream of the finding: verification automation, patch generation and validation, shortening the discover-to-deploy window, and helping under-resourced maintainers and small clients survive the coming deluge of findings. That’s where defensive value is being created right now, and it’s a more interesting place to build a consulting practice than chasing the same low-hanging CVEs an agent will find for free.
Keeping the skeptic’s hat on
A few caveats worth stating, because a practitioner take that swallows the marketing whole isn’t worth reading:
- Anthropic is an interested party. They built the model, they benchmark it, and they have every incentive to make the capability story land. The partner quotes on the Glasswing page are corporate testimonials, not data.
- The independent work is more persuasive than the announcements. ExploitGym and ExploitBench are external, mechanically graded, and reproducible — and they were run with safety filters disabled under structured-access programs, which means these are capability ceilings under ideal conditions, not what a random API key will do. Anthropic’s Cyber Verification Program gates legitimate access, and refusals on standard keys are expected.
- Benchmarks are still benchmarks. Reading a flag in a container is not the same as a chained, OPSEC-aware intrusion against a defended production network with detection and response in the loop. The gap between “exploited in a lab” and “owned a real target quietly” is real — but it’s narrowing, and pretending otherwise is how people get surprised.
Bottom line
Project Glasswing is the moment the industry stopped arguing about whether AI changes offensive security and started arguing about how fast. The honest read of the evidence is that the floor under exploit development has dropped, the constraint has moved from finding bugs to fixing them, and the practitioners who thrive will be the ones who move up the stack — from discovery toward judgment, prioritization, and closing the loop on remediation.
The capability is here. The safeguards, the disclosure norms, and frankly our own habits are lagging behind it. That gap is exactly where the interesting work — and the responsibility — lives for the next few years.
Sources: Project Glasswing and the initial update (Anthropic); ExploitGym (Berkeley RDI et al., arXiv:2605.11086 ); ExploitBench (CMU). Benchmark figures cited as published at the time of writing.
AI security vulnerability research red team exploit development offensive security
1731 Words
2026-06-08 21:00